随着人工智能产业向“生产可用”阶段稳步推进,大模型驱动的智能体开发平台正逐步成为企业智能化转型的核心抓手。近日,由工信部国家工业信息安全发展研究中心(以下简称“国家工信安全中心”)最新发布了《大模型智能体开发平台技术能力综合测试报告》,这是一份面向行业主流智能体开发平台的权威技术能力评估报告,该测试系统评测了国内主流的四大平台在RAG能力、工作流控制与Agent智能体等方面的表现,揭示了当前平台技术能力的技术水平与发展趋势。
多场景能力测评,三大维度解析平台技术关键指标
报告从RAG(检索增强生成)、工作流与智能体(Agent)三大关键能力出发,构建了覆盖文本问答、结构化数据处理、多模态交互、流程控制与工具调用的综合性评测体系。共设计600+个问题,模拟企业级场景,如客户服务、政策咨询、订单处理等,全面还原业务需求。
RAG能力:考查多模态知识处理、任务复杂度应对及交互机制完备性,验证知识检索精度与用户体验平衡;
工作流能力:以订单管理等场景为对象,评估流程稳定性与控制精度,涉及参数提取、异常处理等环节;
Agent交互能力:围绕智能体工具调用智能化水平,检验单工具判断、多工具协同及指令执行效果。
评测结论一:文本问答能力成熟,多模态交互仍存短板
在知识增强机制的测评中,四大平台在文本问答场景展现出较强的基础能力,但在复杂场景处理上分化明显。
文本问答场景中,各平台单文档知识回复准确率均超87%,多文档组合回复准确率超80%,显示出对纯文本信息的检索、整合能力已较为成熟。
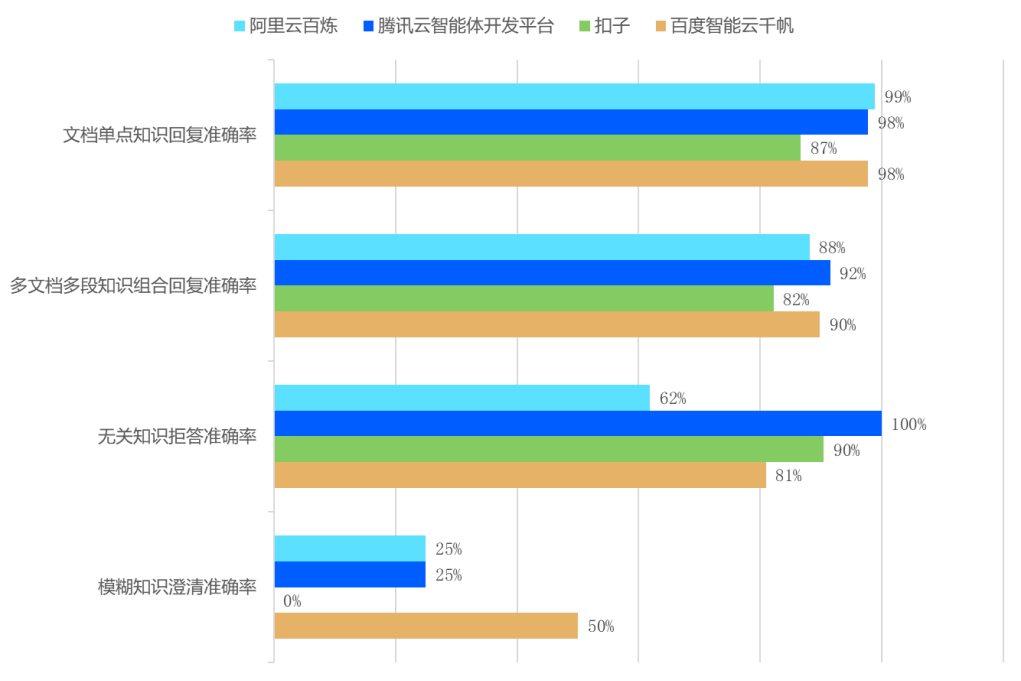
图1:大模型RAG文本问答表现
结构化数据问答场景中,单表查询准确率普遍较高(83%-95%),但多表关联查询成为能力分水岭。测评发现,自然语言解析嵌套条件(如“销售额前五且库存低于警戒值的商品”)、多表关联路径推导仍是行业共性挑战。
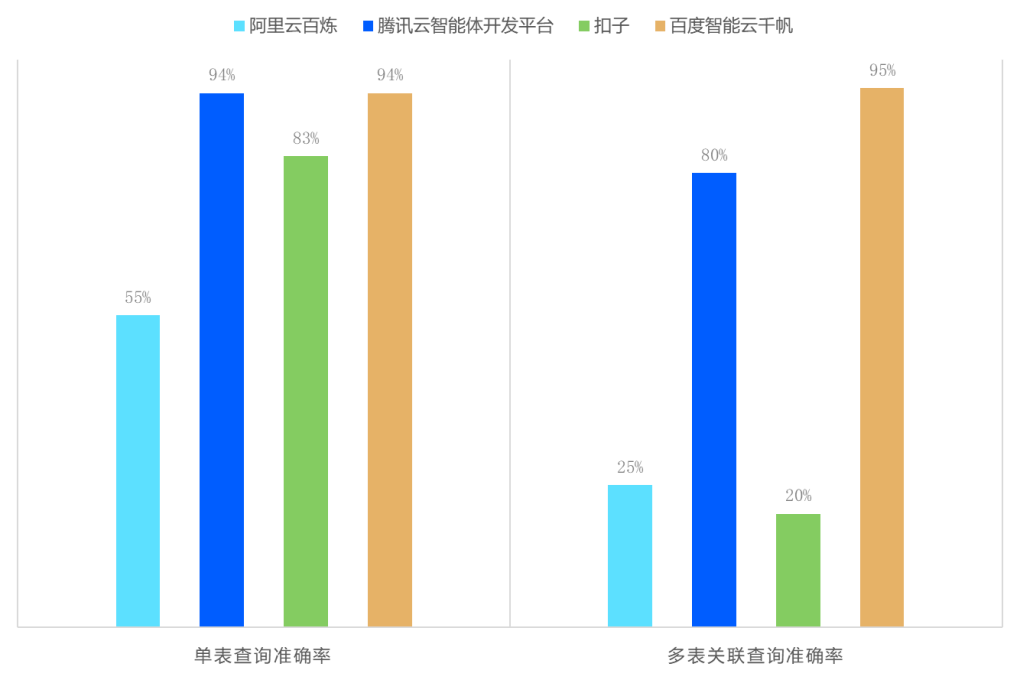
图2:大模型RAG结构化数据问答表现
图文问答场景暴露了多模态协同的短板。尽管各平台均具备OCR图片文字识别基础能力,但在图片内容与文本关联、精准输出相关图片上表现不足。
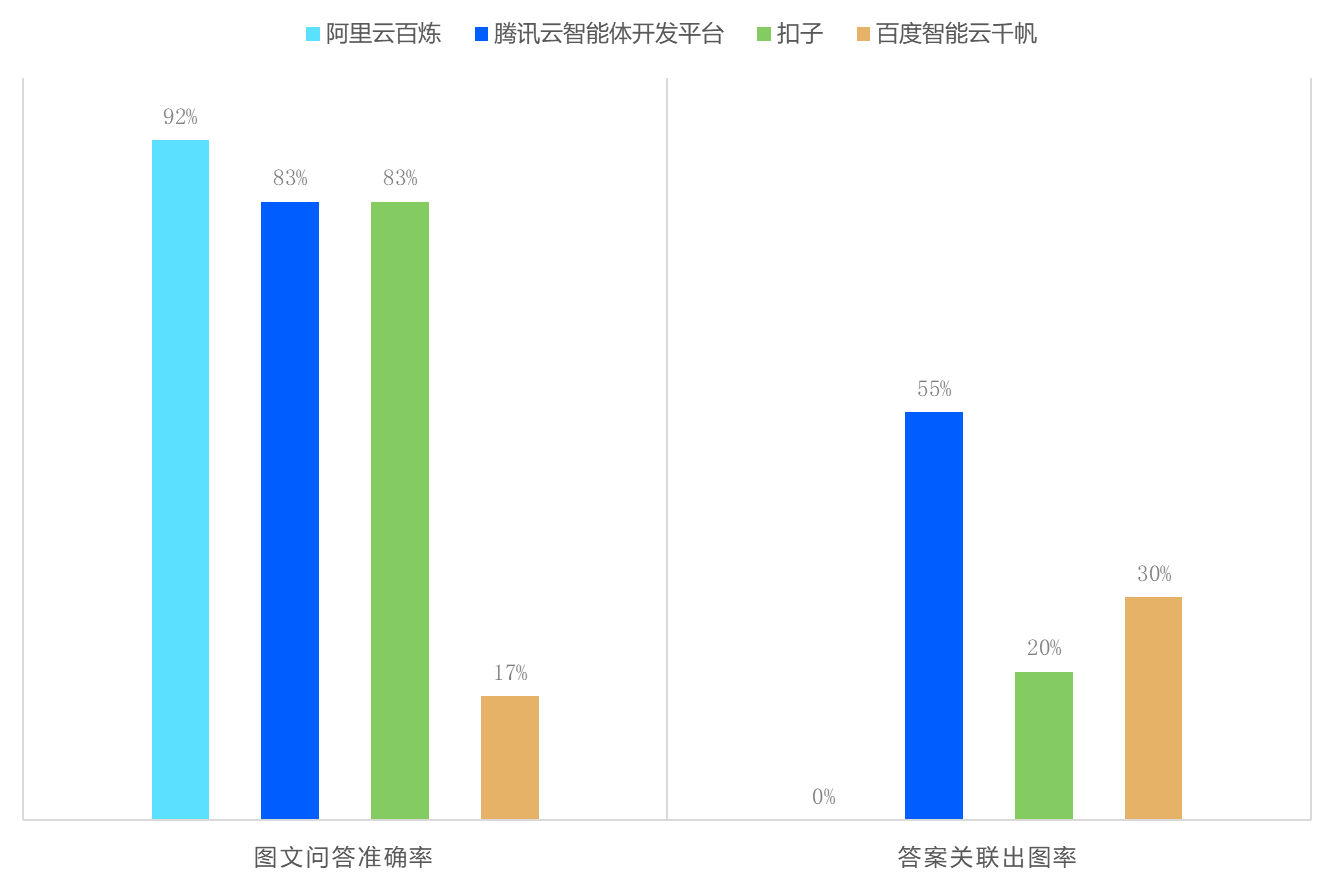
图3:大模型RAG图文问答场景表现
评测结论二:工作流框架基本可用,节点封装和细节调优决定端到端闭环能力和用户体验
工作流作为复杂任务的标准化执行框架,其核心能力体现在流程控制的稳定性与参数管理的精准性。研究以电商客服咨询和订单修改为典型场景,覆盖参数提取、异常回退、意图识别等关键环节,结果显示四大平台整体端到端准确率在61.5%-69.2%区间,呈现基础可用但仍有提升空间的特点。
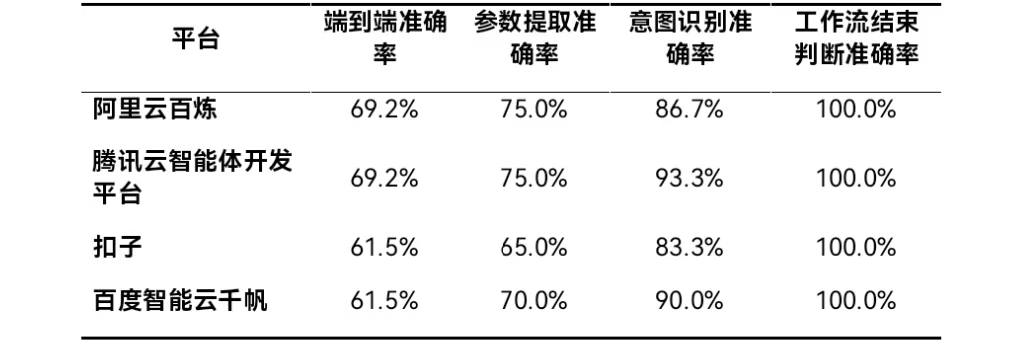
表1:大模型工作流能力表现
工作流评测聚焦订单修改等复杂对话流程。报告指出,不同平台在工作流设计理念与配置体系上存在明显差异。四大平台在流程终止判断上均达100%准确率,意图识别普遍超过85%。不过在参数提取、流程回退方面仍存在分化,百度与扣子平台在混淆字段提取中出现较多错误。
图4:不同平台工作流组件
评测结论三:Agent工具调用基础可用,深度协同与生态成关键
智能体(Agent)的核心价值在于工具调用的智能化与复杂任务处理能力。测评显示,四大平台均已构建基础工具调度机制,在单工具调用与基础意图识别上具备可用性,但多工具协同与生态深度成为能力分化的关键。
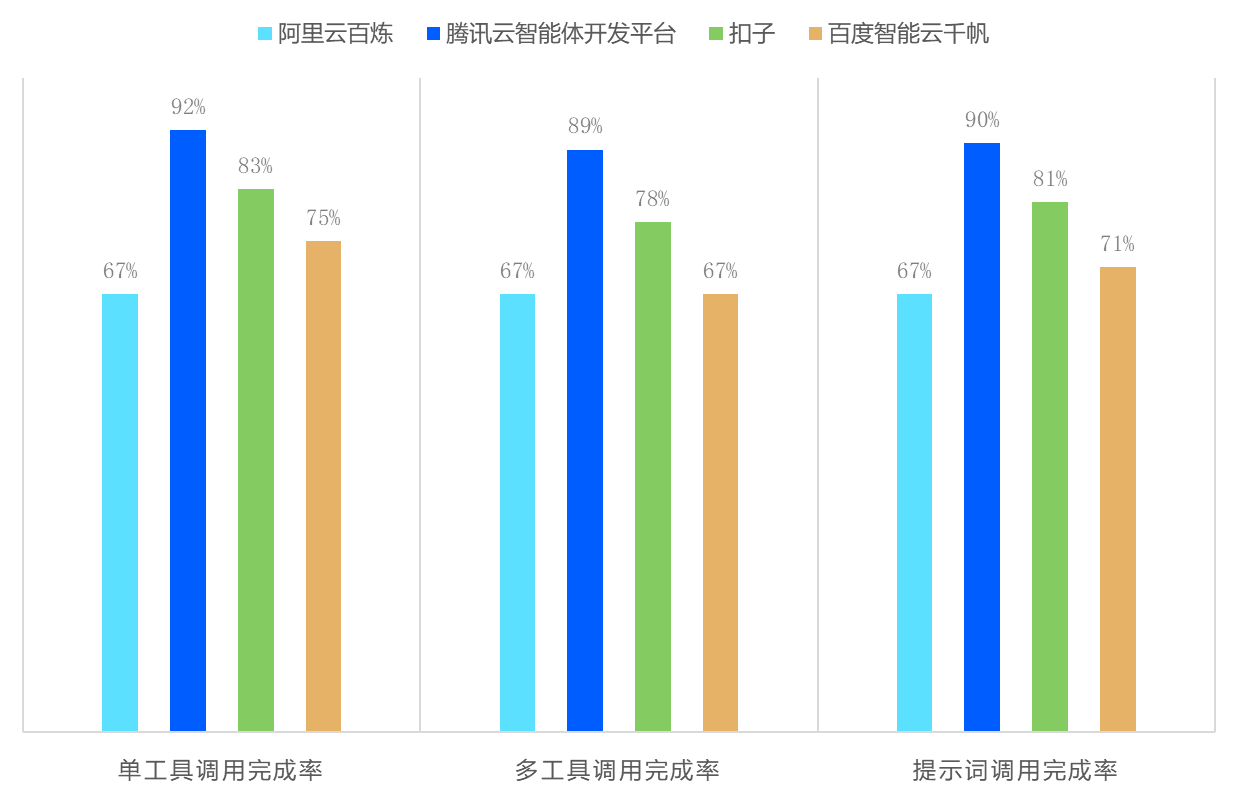
图5:大模型Agent能力表现
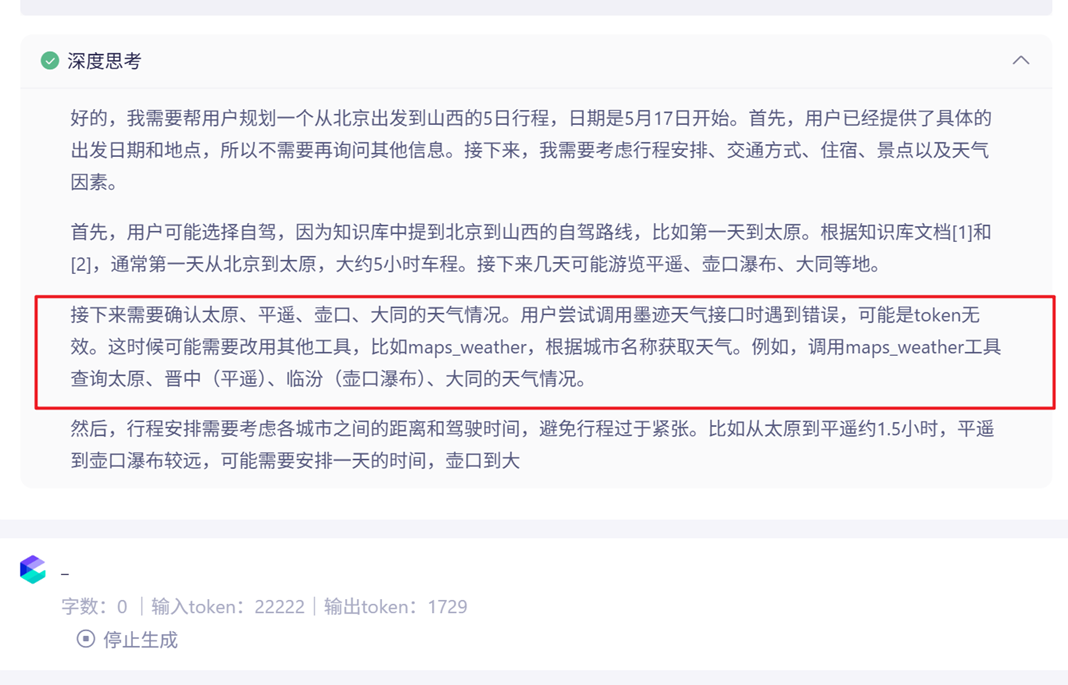
图6:错误案例-天气工具鉴权失败
报告总结:平台能力逐步收敛,竞争转向“技术链”与“生态力”
综合测评结果,当前大模型智能体开发平台呈现“基础能力趋同,产品路径分化”的竞争格局。在文本处理、基础流程控制等标准化场景,各平台能力已较为接近;但在复杂场景处理(如多表关联查询、多工具深度协同)、多模态协同及工具生态建设上,差异逐步显现。
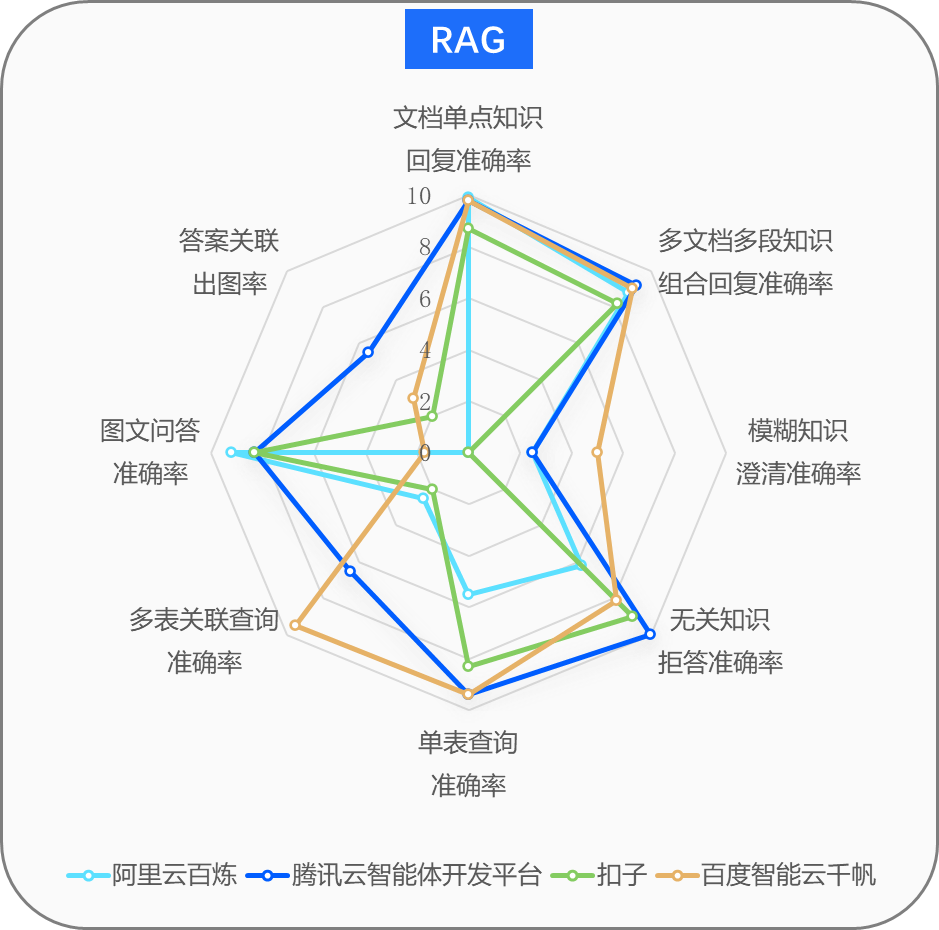
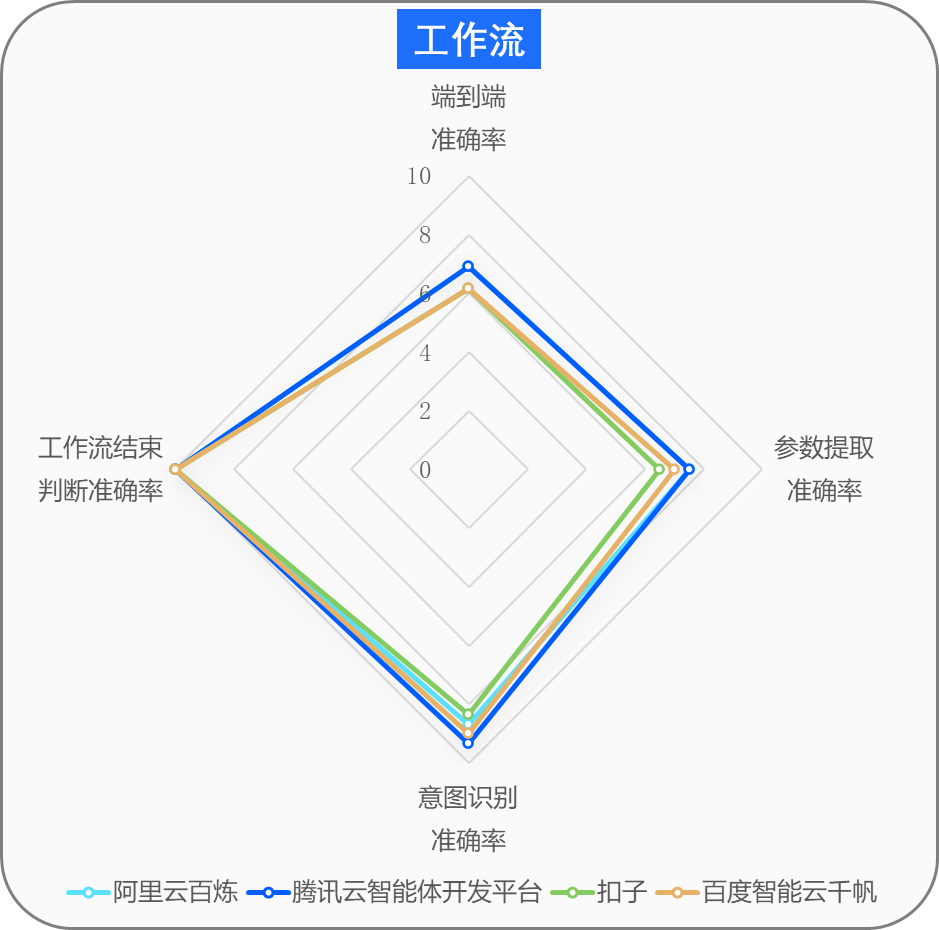
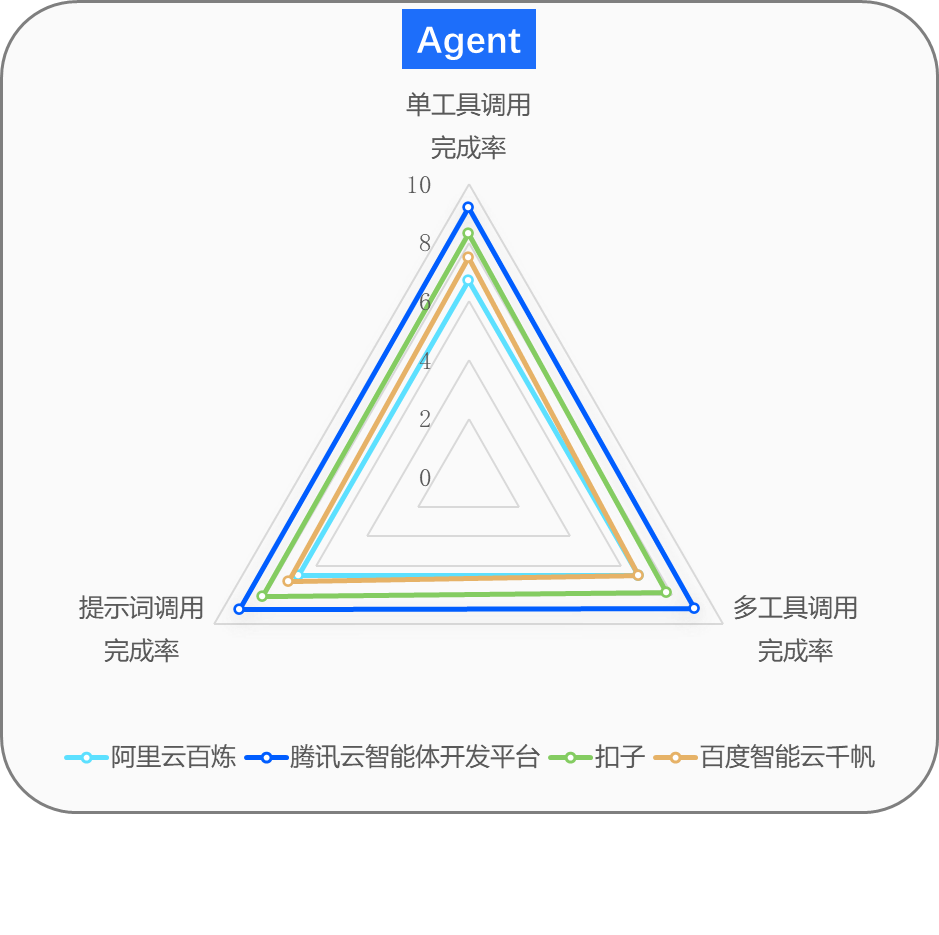
图7:大模型智能体开发平台评测表现总览
未来,大模型智能体开发平台需跨越三大门槛:场景深度适配以实现业务与模型能力的精准耦合、技术链厚度构建以强化流程自动化与工具闭环、生态广度拓展以完善垂直行业工具适配。随着各平台在生态建设与细节优化上的持续投入,大模型智能体有望从“技术演示”加速迈向“生产可用”的成熟阶段。
从整体评测结果看,平台在基础能力层面已趋同,但在多模态协同、流程恢复能力、工具生态建设等方面仍存在分化。
报告预测,未来平台竞争将转向三大方向:一是场景深度适配能力,二是技术链的完整性与自动化程度,三是生态拓展广度与垂直行业工具集成能力。(龚新)




请输入验证码